Evaluation Metrics
Nhân dịp không họp mấy tuần nay, mình làm 1 bài tổng hợp kiến thức về metrics ha mấy bạn. Tui sẽ cố gắng diễn đạt được vấn đề về evaluation metrics một cách intuitive nhất, nhưng vẫn đầy đủ kiến thức nhất có thể, hi vọng nó sẽ giúp ích được mọi người.
Bài này sẽ gồm những phần sau:
- Ôn tập những metrics cơ bản
- Thảo luận về những loại metrics được dùng trong object detection
2.1. Metrics của PASCAL VOC 2007
2.2. Metrics của PASCAL VOC 2010
2.3. Metrics của MS COCO
Okay, bắt đầu thôi
1. Ôn tập về những metrics cơ bản
Theo tui biết thì đây là những loại metrics mà mọi người dùng trong Machine Learning cũng như đã được học trong lớp IDM, trong bài này mình ôn lại xíu để vào những loại metrics mình sẽ áp dụng trong project mình nha.
Như mình đã biết ở bài toán classification, bất kể là bao nhiêu class, mình đều có thể phân ra 1 bảng như sau:
| Labeled True | Labeled False | |
|---|---|---|
| Predicted True | True Positive (TP) | False Positive (FP) |
| Predicted False | False Negative (FN) | True Negative (TN) |
Từ bảng này thì mình sẽ có 3 loại metrics mà đó giờ mình thường dùng nhất: accuracy, precision, và recall và chúng lần lượt được định nghĩa như sau:
- Accuracy: là khả năng của model để tìm ra những thành phần đúng từ sample, được tính bằng công thức:
- Precision: là metrics để biết được mình đã dự đoán bao nhiêu % positive từ tập mình đã predicted là “positive” và được tinh bằng công thức:
- Recall, hay còn được gọi là độ nhạy (sensitivity) của model hoặc true positive rate: là metrics để biết được mình đã dự đoán bao nhiêu % positive từ tập đã được labeled là “positive” và được tính bằng công thức:
Bên cạnh những metrics trên, tụi mình cũng thường thấy những metrics như: true negative rate ( hay specificity ), F1-score, etc.
Định nghĩa thì dễ rồi, nhưng câu hỏi được đặt ra là mình sẽ infer được điều gì từ những metrics này và sẽ phải xử lý như thế nào nếu không đạt được kết quả mong muốn? Mình lấy ví dụ đơn giản ở việc test virus ha (cho nó gần gũi :v ), mình sẽ có bảng như sau, trong trường hợp này t tạm dùng từ nhiễm và không nhiễm thay vì âm tính và dương tính để tránh bị nhầm lẫn với cái negative và positive ở metrics của mình ha:
| Thực sự nhiễm virus | Thực sự không nhiễm virus | |
|---|---|---|
| Dự đoán bị nhiễm | True Positive (TP) | False Positive (FP) |
| Dự đoán không nhiễm | False Negative (FN) | True Negative (TN) |
Giả sử mình nói độ chính xác (accuracy) của bộ test mình là 100%, độ nhạy (sensitivity hay recall) của bộ test mình là 95%, specificity (không biết dịch sao luôn :( ) là 87%, precision hay positive predictive value là 84% thì những thông số trên có nghĩa là gì?
- Độ chính xác 99% có nghĩa là trong số 100 người, bộ test mình có thể đoán đúng đến 99 người, bất kể 100 người kia có bao nhiêu người thực sự không nhiễm hay đã nhiễm virus. Vì accuracy không quan tâm đến mật độ người thuộc từng class, dù bảo 99% acc thì nghe ngầu đấy, nhưng vẫn gây quan ngại lớn về khả năng của bộ test mình.
- Độ nhạy 95% ở đây nói rằng trong số 100 người thực sự đã nhiễm virus, bộ test mình dự đoán đúng được 95 người, 5 người còn lại sẽ là False negative, tức là người đã nhiễm virus nhưng do test là không nhiễm nên họ đã được thả long nhong ngoài đường (oh no…)
- Specificity 87% nói lên trong 100 người không nhiễm virus, bộ test mình đã đoán đúng được 87 người không nhiễm ( true negative), và 13 người còn lại đã bị oan
- Precision 84% đã nói rằng trong 100 người được chẩn đoán là nhiễm virus, mình đã đoán đúng được 84 người đã nhiễm (true positive), và again 16 người vốn không bị nhiễm virus thì giờ bị xem là bị nhiễm
Từ việc phân tích trên, mình thấy là một bộ test tốt sẽ là bộ test giảm thiểu được 2 loại error: false negative, tức người đã bị nhiễm virus nhưng được test là không nhiễm virus, và false positive, tức người không nhiễm virus nhưng bị chẩn đoán là nhiễm virus. Tuy nhiên, sẽ luôn có trade-off giữa sensitivity và specificity, vậy nên mình thấy ROC curve luôn có hình dạng tương tự như vầy:

Điều này thì tui rút trích từ kinh nghiệm, nếu recall hay precision quá thấp trong khi cái còn lại thì cao, hãy xem imbalance của dataset của mọi người. Còn những tình huống còn lại nếu bị thấp 1 metric thì có thể thêm dữ liệu hoặc tăng độ phức tạp của thuật toán mọi người dùng.
Trong đợt vừa rồi, tụi mình cũng dùng IoU (intersection over union) để xác định xem trong số gương mặt mình localize được, đâu là box trùng với labeled box. Công thức cửa IoU được tính tương tự như Jaccard coefficient
Mọi người có thể xem thêm hình minh họa dưới đây

Vậy là mình đã review lại 1 số metrics cơ bản, tiếp đến mình sẽ đào sâu vào metrics được dùng ở bài toán Object Detection như thế nào.
2. Thảo luận về những loại metrics được dùng trong object detection
Bất kể một model object detection là single-stage hoặc two-stage, metrics được dùng trong các model này đều phải thỏa mãn cả 2 phase: localization và classification. Như mọi người thấy thì đợt vừa rồi mình dùng IoU cho việc phát hiện ra box đúng, và accuracy để đưa ra độ chính xác của model cuối cùng, tuy nhiên, cách làm này có rất nhiều hạn chế do chỉ mới đánh giá độ chính xác của model ở 1 thời điểm và 1 ràng buộc duy nhất về IoU. Hiện tại, để đánh giá model object detection, mình cần quy về 1 loại metric chuẩn, đó là mean Average Precision (mAP) và mean Average Recall (mAR), đôi lúc chỉ là AP hay AR, tuy nhiên tùy theo challenge thì người ta sẽ có cách tiếp cận metrics này khác nhau, ví dụ như:
- PASCAL VOC: ở challenge 2007 thì dùng Precision-Recall curve và Average Precision. Sau đó đã đổi lại dùng Area Under Curve trên Precision. Chỉ dùng threshold 0.5 cho IoU
- MS COCO: sử dụng nhiều threshold cho IoU và dùng nhiều loại mAP
- Google Open Image V4: dùng mAP cho 500 class
- ImageNet
Trong bài này, t sẽ chỉ tập trung mAP (mAR có thể đc suy ra tương tự) được tính bởi PASCAL VOC và MS COCO.
2.1. PASCAL VOC 2007
Trong hướng tiếp cận này, để tính mAP, mình cần tính AP trước, và để tính AP, mình cần tính Precision và Recall cho từng class cộng với việc mình sẽ quan tâm đến IoU ngay tại bước này luôn. Tui lấy ví dụ ở project tụi mình ha, mình sẽ có 3 class: no_mask, correct_mask và incorrect_mask đúng không, vậy thì lấy ví dụ ở 1 class là correct mask, lưu ý là mình nên tập trung đúng 1 class này lúc này thôi nhé. Các bước tính sẽ được thực hiện như sau:
- Sắp xếp các box detect được của các hình theo thứ tự giảm dần của confidence của class correct mask. Bước này cần thực hiện do VOC2007 quan tâm đến rank của output, nhưng ko thi VOC thì bước này không cần nhé :v. Khi đó mình sẽ có 1 bảng các box thuộc class correct mask và không bị lẫn với những class khác
- Nếu 1 box có IoU với labeled box >=0.5, mình đánh dấu lại nó là True (predicted) còn không thì đánh là False và đồng thời tính precision và recall cho box đó như sau:
- Sau khi hoàn tất cho tất cả các box, mình có được PR curve, và có thể tính Average Precision. Ở VOC2007, người ta dùng 1 phương pháp cho rải đều 11 điểm nội suy (interpolation points) lên đường PR này theo recall levels từ 0 đến 1 với step là 0.1, và tính trung bình precision từ 11 điểm đó bằng công thức:
, trong đó r là recall, còn được tính bằng công thức:
, với là điểm recall có precision lớn nhât tính từ trở đi. Ví dụ như trong hình sau:
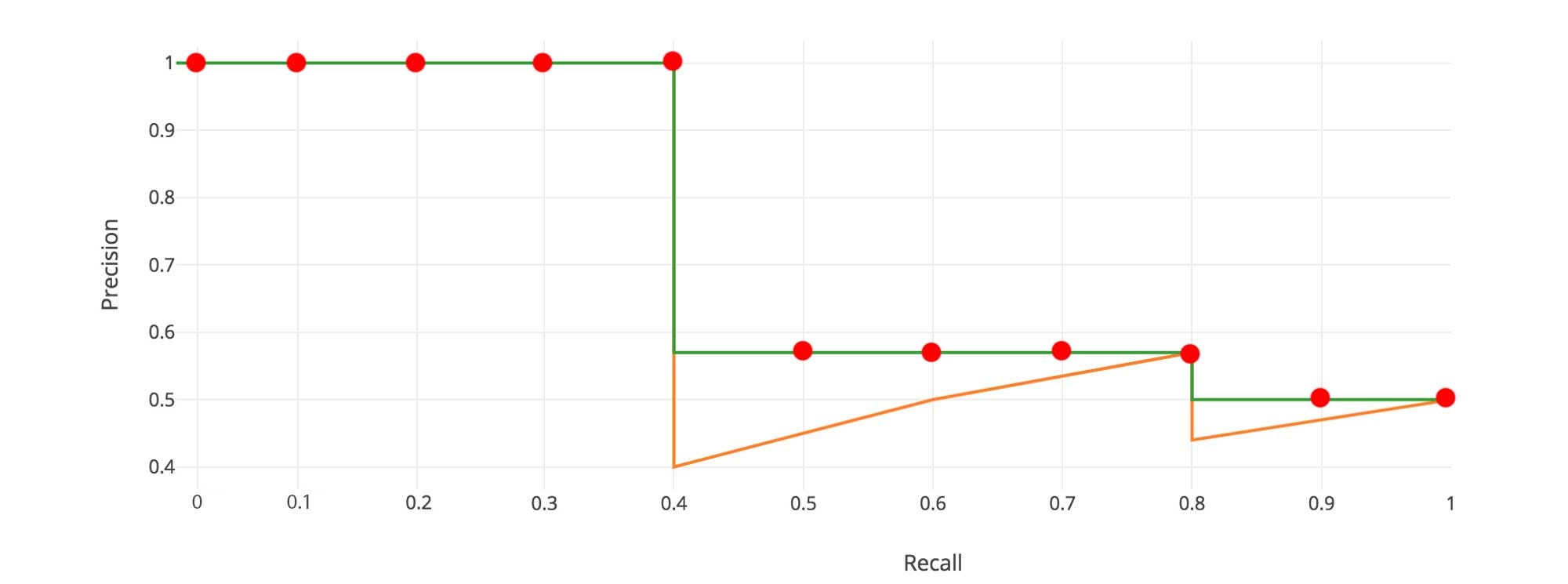
Đường màu cam chính là đường PR thật, còn đường màu xanh là đường đã tính , ví dụ những điểm tại recall bằng 0.5, 0.6, 0.7, precision của chúng đã được đưa ngang bằng mức 8. Giả sử đó là đường PR cho correct mask class, dùng công thức tính AP, mình sẽ có - Lặp lại những bước trên cho 2 class còn lại, mình sẽ có 3 AP cho từng class. Việc của mình bây giờ chỉ là lấy mean AP cho 3 class thôi ( tổng 3 AP chia 3 :D )
2.2. PASCAL VOC2010
Khi này, cách làm của mình ở phía trên gần như không thay đổi, chỉ thay đổi lại 1 công thức của AP
Dù ở cả 2 hướng của VOC, AP đều là “area under PR curve”, từ năm 2010 trở đi, AP không chỉ quan tâm 11 điểm thôi mà cho tất cả các điểm luôn.
2.3. MS COCO
Hiện tại, kết quả sử dụng metric của COCO dường như nhiều hơn cho những model đạt benchmark. Thay vì tính AP cho từng class, rồi tính mAP cuối cùng theo số class như VOC, COCO quan tâm đến threshold của IoU với mục đích siết chặt độ chính xác của phần localization, vậy nên hướng tiếp cận sẽ là: tính AP cho từng threshold của IoU, sau đó tính mAP theo số threshold đã dùng. COCO có những loại AP như sau:
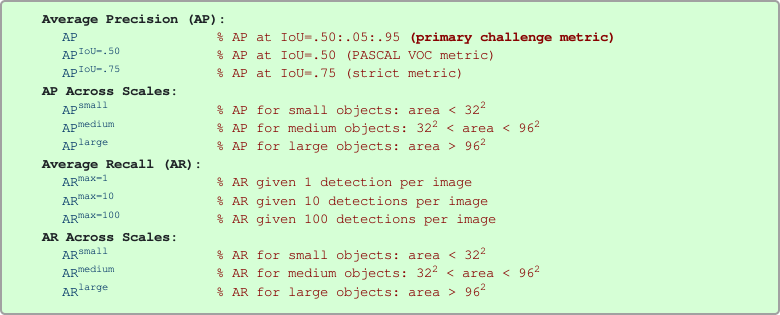
Nhưng mình chỉ cần tập trung 3 metrics thuộc Average Precision là sẽ giải thích và tính đc những metric còn lại của họ. Mọi người có thể thấy trong đây ghi hay AP@.5 chính là PASCAL VOC metric, thật ra nó là PASCAL VOC metric (IoU threshold = 0.5), nhưng thay vì với 11 interpolation points, họ dùng tới 101 điểm, trong nhiều bài paper thì có thể dùng công thức integral luôn. Sau đó cũng tính mAP theo average các class. Tương thì thì hay AP@.75 cũng được tính tương tự như vậy, nhưng cho IoU threshold = 0.75. Vậy thì còn AP (primary challenge metric) ? Cách tính của nó sẽ được thực hiện như sau:
- Với mỗi class, mình sẽ cho IoU threshold chạy từ 0.5 đến 0.95 vs step bằng 0.05.
1.1 Với mỗi threshold đó, mình sẽ tính AP cho từng cặp IoU và class, tạm gọi là AP[t,c] với t là threshold và c là class. Khi này, AP đó thật ra chính là AP ở bước thứ 3 của PASCAL VOC
, trong đó r là recall, còn , và N là số interpolation points.
1.2 Sau đó, mình sẽ tính mean AP cho threshold theo từng class.
với T là tập các threshold từ 0.5 đến 0.95 với step bằng 0.05 - Sau đó, mình sẽ tính mAP cuối cùng bằng cách lấy trung bình các
với C là tập các class của mình.
Vậy thì mình có công thức tổng quát:
Okay, vậy là xong công thức mAP cho COCO, lợi thế ở đây là mAP của COCO có độ tổng quát nhiều hơn nếu chỉ dùng 1 threshold. Cơ mà bài dài vậy thôi chứ người ta mới tạo 1 cái tool cho dùng cả GUI cho vụ này r (1 tool t đã tìm được) :v mn yên tâm ha, ghi để mình hiểu tới lúc báo cáo còn biết đường nói :v
Vậy là xong phần metrics, vài ngày sau t hi vọng sẽ có bài về loss function cho mọi người ha. Chúc mọi người làm việc tốt
Written by Phung Khanh Linh