Loss functions
Hôm nay stackEdit sập mất r :) giờ phải viết trên app mới đây :)) (cơ mà app mới có support theme khá là đẹp :v) Anyway, hôm nay mình đi vào một trong những nội dung chính của DL mà mình sẽ cần cho model của mình - loss function (hàm mất mát). Bài viết này gồm những phần chính như sau:
- Overview về loss function
- Những loss function cơ bản
- Loss function trong object detection
Hic.. mỗi lần viết tui cũng phải đọc rất nhiều, và tìm cách sao để ghi cho mọi người dễ hình dung nhất(dĩ nhiên viết xong rồi thì t khá thỏa mãn :v), nên mọi người nhớ đọc nhé, không hiểu chỗ nào có thể hỏi tui nha. Giờ mình bắt đầu thôi
1. Overview về loss function
Đầu tiên, mình ôn lại lần thứ 3,4 gì đó về cơ chế vận hành của 1 node của 1 Neural Network.
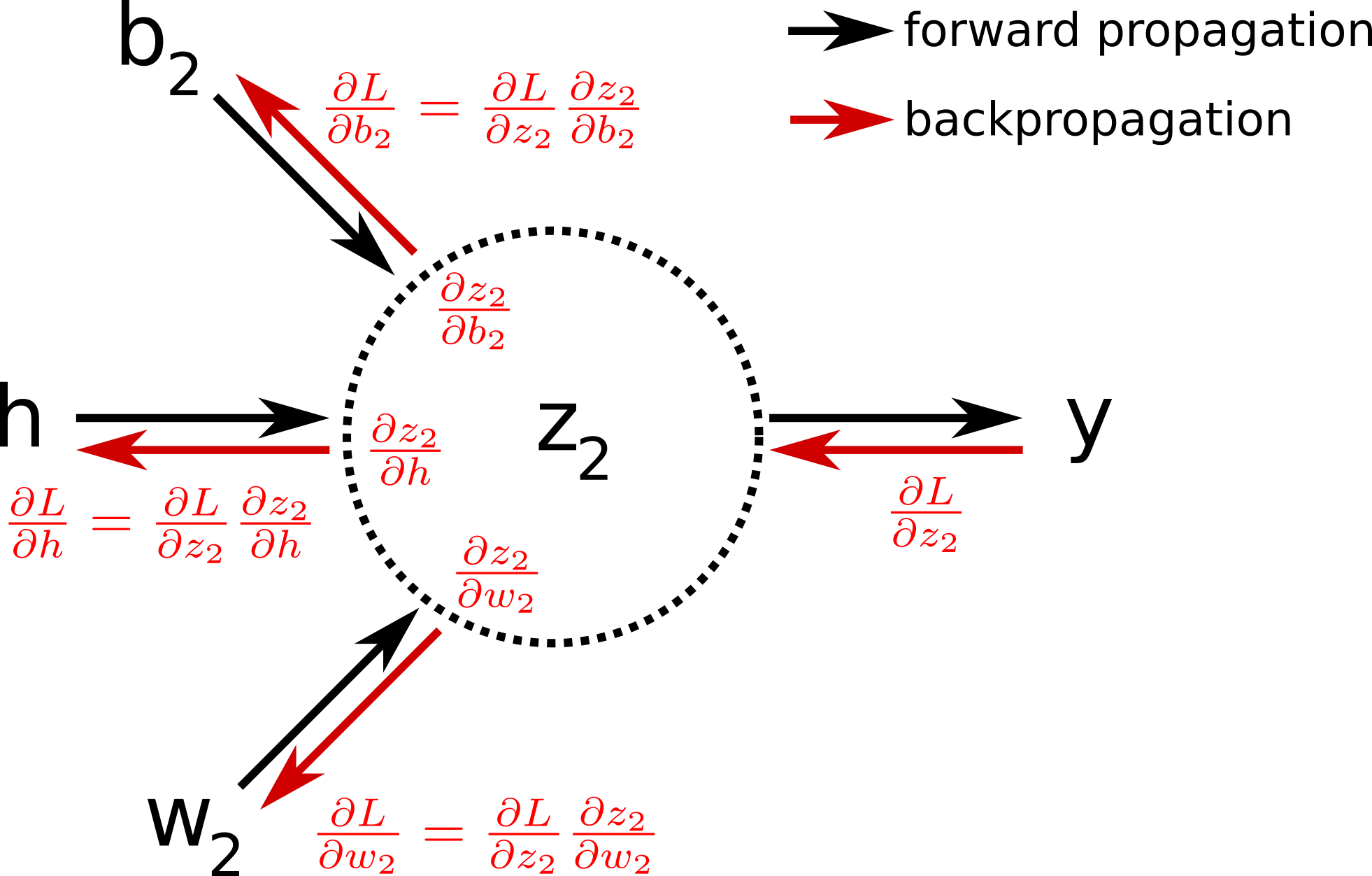
Như mọi người đã học, 1 node của 1 NN sẽ nhận vào 1 list các feature có kết nối ở node trước đó của nó (ở đây là vector h), 1 weight (w2) và bias. Node này sẽ đi qua 1 hàm linear \(z= \sum{w_i*x_i}+b_i\), sau đó được update thông qua 1 hàm activation function và trả về output y, output này có thể là vector h cho node sau, hoặc là probability cho final output.
Khi đi vào bước backprop, mình sẽ thông qua 1 hàm để tính loss (lưu ý hàm này không phải activation function nhé) giữa giá trị mình đạt được ở output và giá trị thật của output đó, rồi tính đạo hàm của hàm L theo từng tham số, update những tham số theo đạo hàm đã tính được. Từ đây thì mình thấy được, việc chọn loss function có ảnh hưởng đến những yếu tố như tốc độ học (training time) của model, accuracy của output, tính tổng quát của model khi update tham số, etc. Vậy thì chọn loss function như thế nào là phù hợp và làm sao để giải thích tính đúng đắn của nó? (uầy, rõ ràng là chỉ là 1 đống log và 1 đống prob kết hợp với nhau thôi mà đúng ko :)) )
Để trả lời câu hỏi trên thì mình sẽ lướt sơ 1 xíu về information theory (1 branch mà đáng lẽ tụi IT mình phải đc học trong đại học :) ). Information theory là 1 branch của toán giúp mình biết được với 1 signal nhất định, mình sẽ lấy được bao nhiêu “thông tin” từ nó. Kim chỉ nam của information theory chính là một sự kiện xảy ra bất thường và độc lập sẽ thu lại được lượng thông tin lớn hơn những sự kiện thường xuyên và phụ thuộc. Vậy nên từ giờ về sau, hễ mà gặp từ information mình sẽ nghĩ ngay đến “uncertainty” hay “surprise” liền :D. Từ đó mình sẽ có 1 đại lượng cơ bản nhất để đo thông tin, gọi là self-information, được định nghĩa: \[I(x)=-ln (P(x))\] Đơn vị được dùng là nats, 1 nat tương đương 1 lượng thông tin thu được từ sự kiện có khả năng xuất hiện là \(\frac{1}{e}\) . Nếu mình dùng log-2 thì đơn vị sẽ là bits hoặc shannons. Nhưng self-information chỉ dùng để đo lượng thông tin từ 1 event, vậy thì làm sao để mình trích xuất thông tin từ 1 distribution? Mình sẽ dùng Shannon entropy để định lượng lượng thông tin của cả distribution, hay nói cách khác, nó chính là expected value, là trung bình của information trên 1 distribution, và được định nghĩa: \[H(x)=E_{x\sim P}[I(x)]\], với \(x\sim P\) là 1 biến x tuân theo distribution P. Vậy, nếu \(X\) là discrete thì entropy sẽ trở thành: \[H(x)=-\sum_{i=1}^np(x_i)ln(p(x_i))\]nếu \(X\) là continuous thì entropy sẽ được tính bằng: \[H(x)=-\int_X p(x)ln(p(x))dx\]. đây \(p(x)\) có thể là probability mass function hoặc probability density function
Có thể nói Machine learning được kế thừa kha khá từ information theory, đặc biệt là khi phát triển loss function. Tuy nhiên ở đây tui chỉ có thể nói sơ cho mọi người, cụ thể có thể tham khảo thêm ở đây nhé Link information theory. Giờ mình sẽ qua phần 2 để nói về 1 vài loss function cơ bản
2. Những loss function cơ bản
Đa phần loss function cơ bản sẽ được chia thành 2 loại: regression và classification. Mặc dù ở cả 2 loại, mình đều cần tính difference giữa \(y\) và \(\hat y\) và tập trung minimize tổng của các difference đó, ở regression, output sẽ là 1 số thực hoặc là 1 vector số thực, ví dụ như giá nhà, giá cổ phiếu dự đoán được. Trong khi đó, ở classification, output của mình là probability và có thể được convert sang class, khi này số lượng phần tử của các class ảnh hưởng đến khả năng của loss function, và sẽ được đề cập ở phần 3.
2.1. Huber Loss
Mình đã học nhiều loss function cơ bản rồi đúng không? Trong đó có 2 loss functions cơ bản mà có ngủ thì hỏi cũng phải nhớ đến đó là L1 và L2. 2 loss functions này có thể được kết hợp lại thành Hubert loss và được định nghĩa như sau:
\[L_\delta(y,\hat y)=\begin{cases}\frac{1}{2}(y-\hat y)^2,\ if\ |y-\hat y|\leq \delta \\ \delta|y-\hat y| - \frac{1}{2} \delta^2,\ otherwise \end{cases}\], với \(\delta\) tùy chọn, \(\frac{1}{2}\) được thêm vào để hàm dễ lấy đạo hàm
Ở đây mình thấy hàm Huber sử dụng L1 khi distance giữa \(y\) và \(\hat y\) được cho là lớn, điều này giúp tăng tốc độ đạt extremum cho hàm. Hàm sẽ có đồ thị như đường xanh lá trong hình sau:

Nếu chỉ dùng L1, hàm xanh lá này sẽ tạo ra đồ thị hình chữ V và sẽ không thể đạo hàm được ở \(x=0\), do vậy, mình cần thay đổi L1 thành L2, để mình có thể tính đạo hàm tại minima, đồng thời giảm tốc độ tiến đến minima để mình đảm bảo mình sẽ không miss nó.
Huber loss được sử dụng trong bài toán regression, tuy nhiên hàm này lại không được dùng thường xuyên cho object detection cho lắm.
2.2. Kullback-Leibler Divergence Loss
KL divergence giúp mình xem xét sự khác biệt giữa 2 distribution mong muốn. Do so sánh luôn cả 2 distribution, mình sẽ có lợi thế khi dùng nó làm loss cho multi-class loss. Trong information theory, Kullback-Leibler divergence loss giữa 2 distribution \(P\) và \(Q\) được định nghĩa như sau: \[D_{KL}(P||Q)=E_{x\sim P}[log\frac{P(x)}{Q(x)}]\] và có thể được viết lại dưới dạng cost function: \[J_{KL} = \sum_{i=1}^mP(x)log[\frac{P(x)}{Q(x)}]\] Tuy nhiên, do KL có tính asymmetric, tức \(D_{KL}(P||Q)\neq D_{KL}(Q||P)\) , khi sử dụng mình phải xem xét kỹ coi sẽ dùng \(D_{KL}(P||Q)\) hay \(D_{KL}(Q||P)\). Để khắc phục tình trạng này, mình sẽ đến với cross entropy loss
2.3. Cross Entropy Loss
Cross entropy loss là hàm loss được sử dụng khá là rộng rãi, rộng rãi ở 1 mức độ nếu mọi người học course Deep Learning của Andrew Ng thì đây sẽ là 1 trong những hàm hàm mà ổng giới thiệu đầu tiên ấy :v. Đầu tiên, mình sẽ có probability để 1 element thuộc vào 1 class là \(p\). Vậy thì probability để 1 element không thuộc vào class đó sẽ là \(1-p\). Mình sẽ thêm -log vào mỗi probability này để nó thể hiện “self-information”. Từ đây thì mình sẽ có piece-wise function cho 1 output: \[L=\begin{cases}-log(p),\ if\ \hat y=1 \\-log(1-p),\ if \ \hat y=0 \end{cases}\], với 1 lúc này là class mình mong muốn
Vậy thì mình có thể tổng hợp công thức lại thành: \[L(1,\hat y) =-\hat ylog(p)-(1-\hat
y)log(1-p)\], với m là số element được input. Vậy, cost function sẽ thành \[J(1,\hat y) =-\sum_{i=1}^m\hat y_ilog(p_i)+(1-\hat y_i)log(1-p_i)\]
Phía trên là định nghĩa của binary cross entropy loss, công thức này cũng dễ được mở rộng ra thành categorical cross entropy loss: \[L(y, \hat y) = - \sum_{i=1}^m\sum_{j=1}^c \hat y_{ij}log(p_{ij})\], với c là số class mà mình mong muốn, \(y\) sẽ là 1 vector \(y=[y_{i,1}, y_{i,2},…,y_{i,c}]\), \(\hat y\) sẽ là 1 nếu kết quả predict thuộc cùng class với \(y\) và bằng 0 nếu ngược lại
Okay, vậy là tạm xong phần 2. Ở phần trên tui có đề cập giữa loss function và cost function, loss function là 1 hàm riêng lẻ, cost function lại là tổng của các loss function, nhưng khi mọi người đọc paper, thường là sẽ thấy người ta không phân biệt như vậy nữa, mà gọi chung là loss function luôn. Bên cạnh đó, đây là những loss function được recommend là nên thử đầu tiên, tuy nhiên tùy thuộc vào bản chất stochastic của ML/DL, mình nên chạy 1 model nhiều lần để quyết định loss function phù hợp nhất, tức loss function phải luôn converges và đạt kết quả cao.
3. Loss function trong object detection
Okay, nãy giờ khởi động vậy đủ rồi :D, giờ mình sẽ vào phần 3 này để hiểu tại sao object detection đa phần phải “biến tấu” loss function và những loại loss function nào đang phổ biến cho object detection hiện nay. (Đùa chứ này phần cuối, mọi người yên tâm :v)
3.1. Multi-task loss function
Như mình đã được biết one-stage object detection bao gồm ít nhất 2 task: localization và clasification. Localization thật ra chính là regression để tìm bounding box thích hợp, còn classification thì như tên của nó :) Vậy thì trong 1 model object detection cần phải có 2 ít nhất 2 loại loss, điều này dẫn đến multi-task loss (1 hướng tiếp cận lớn hơn của multi-task loss là multi-task learning). Giờ mình sẽ tìm hiểu thử multi-task loss được dùng như thế nào trong những model đạt bench mark ha.
Yolov1
Yolov1 dùng 1 multi-task loss \(L = L_{loc}+L_{cls}\), với \(L_{loc}\) là localization loss còn \(L_{cls}\) là loss cho classification. Cả 2 đều dùng L2 loss, trong đó \(L_{loc}\) được định nghĩa như sau: \[L_{loc}=\lambda_{coord} \sum_{i=0}^{S^2} \sum_{j=0}^B 1^{obj}_{ij}[(x_i-\hat x_i)^2+(y_i-\hat y_i)^2+(\sqrt{w_i}-\sqrt{\hat w_i})^2+(\sqrt{h_i}-\sqrt{\hat h_i})^2\], với \(S*S\) là số grid có trên 1 khung hình, \(B\) là số bounding box của 1 grid cell, 1 cell sẽ có 1 indicator \(1^{obj}_i\) để biết trong cell này có object nào hay không, \(x,y,w,h\) lần lượt là coordinate và width, height của 1 bounding box. Còn classification loss sẽ được định nghĩa như sau: \[L_{cls} = \sum_{i=0}^{S^2} \sum_{j=0}^B(1^{obj}_{ij}+\lambda_{noobj}(1-1^{obj}_{ij}))(C_i-\hat C_i)^2+\sum_{i=0}^{S^2} 1^{obj}_i\sum_{c\in C}(p_i(c)-\hat p_i(c))^2\], với \(C\) là set of class, \(C_i\) là confidence score.
Ở đây 2 hàm này là hàm L2 có quan tâm thêm cơ chế stablized model thông qua 2 tham số \(\lambda_{noobj}=0.5\) và \(\lambda_{coord}=5\). \(\lambda_{coord}\) có giá trị lớn hơn \(\lambda_{noojb}\) để thay đổi weight của localization loss function, nếu 1 bounding box detect được không có object dẫn đến classification sai thì rõ ràng mình nên phạt chức năng localization nhiều hơn đúng không :v.
Lợi ích của việc dùng L2 cho cả localization và classification là tính đồng nhất trong việc lấy đạo hàm của các hàm, tịnh tiến đến extremum tương đối nhanh. Việc họ dùng thêm indicator, căn cho width và height, và 2 tham số nêu trên cũng góp phần cải thiện những nhược điểm được đề ra trong paper. Tuy nhiên, khi này, hàm này tương đối phức tạp, cũng như không vận dụng được hết những ưu điểm của những loại hàm khác, dẫn đến việc khi define hàm có cách tiếp cận khá là “exhaustive”, họ phải tìm lỗi, rồi sửa, rồi lại tìm và sửa :)
Mọi người có thể tham khảo bài báo ở đây YoloV1
RetinaFace
Đúng rồi, model của mình dùng cho phần localization ấy. RetinaFace sử dụng RetinaNet làm backbone, nên những cái như Feature Pyramid không phải đặc trưng của RetinaFace. Tuy nhiên, việc sử dụng multi-task loss lại cho mình 1 cách nhìn khác (có thể RetinaFace có học hỏi từ những bài khác, nhưng do tui chưa tìm thấy nên tạm lấy nó làm ví dụ nha). Loss của RetinaFace bao gồm 4 thành phần:
-
\(L_{cls}\): classification loss
Loss này được dùng binary cross entropy loss để classify 1 bounding boss có phải là gương mặt hay không
-
\(L_{box}\): bounding box loss
Loss này sử dụng Huber loss cho bài toán regression giữa ground-truth box và detection-box, với 1 box sẽ là 1 vector \(t=[t_x,t_y,t_w,t_h]\).
-
\(L_{pts}\): facial landmark loss
Do ở đây họ làm regression cho cả facial landmark, nên sẽ có thêm 1 loại loss cho task này. Loss này cũng dùng luôn Huber loss tương tự như bounding box loss phía trên cho các vector tượng trưng cho 5 facial landmark: \(l=[l_{x1},l_{y1},...,l_{x5},l_{y5}]\).
-
\(L_{pixel}\): dense regression loss
Ở đây do họ phải render 1 cái 2D face để so sánh pixel-wise với original 2D face (1 cách để validate lại face vừa detect được). Loss function của pixel-wise được định nghĩa như sau: \[L_{pixel}= \frac{1}{W*H} \sum_i^W \sum_j^H ||R(D_{P_{ST}},P_{cam}, P_{ill})_{i,j}-I^*_{i,j}||_1\]
Dense regression loss được tính bằng L1 giữa rendered face R từ 3 tham số: 3D mesh renderer \(D\) theo texture parameter \(P_{ST}\), parameter của camera \(P_{cam}\) gồm \(x,y\) của camera location, camera pose, focal length (không biết họ làm sao để ra cái parameter \(P_{cam}\) được vậy nữa), và illumination parameter 💡 (literally :D) Tất cả các loss này được cộng lại thành 1 loss: \[L=\sum_i^N L_{cls}(p_i,p^*_i)+\lambda_1p_i^*L_{box}(t_i,t^*_i)+\lambda_2p_i^*L_{pts}(l_i,l^*_i)+\lambda_3p_i^*L_{pixel}\]
nhưng khác ở chỗ ở đây họ lại để weight của classification là cao nhất, và \(\lambda_3\) là nhỏ nhất và chỗ này cũng không được giải thích cụ thể.Mặc dù RetinaFace khi đưa vào real-time chậm thật, nhưng cách tiếp cận của họ có điểm thú vị, đó là áp dụng được face render để validate lại solution của mình.
Tạm thời thì phần review 1 vài cách dùng multi-loss function của mình đã xong :)) Giờ mình vào phần cuối (thật ấy)
3.2. Một vài loss function được dùng hiện nay
Bên cạnh những loss function tui đã đề cập thì gần đây người ta có phát triển thêm nhiều loại loss khác:
- Focal loss
- Triplet loss
- InfoNCE
- DR loss
- IoU-based loss: IoU, GIoU, CIoU, EIoU, etc.
Trong list trên thì Focal loss, Triplet loss và InfoNCE là 3 loại loss đang được dùng nhiều nhất (theo paper with code), đặc biệt thì Focal loss được dùng khá nhiều trong các model object detection. DR loss là 1 loại loss được tạo ra với hi vọng cải thiện được điểm yếu của Focal loss. Bên cạnh đó thì các loại loss specified cho bounding box regression cũng được phát triển dựa trên IoU. Do nó khá là nhiều, nên tui hi vọng là sẽ viết thêm cho mọi người ở 1 bài khác, hoặc là nhóm sẽ research chung với tui, sau khi đã hiểu được cơ chế hoạt động của loss fucntion nhé.
Conclusion
Okay, vậy là xong bài loss function như đã hứa với mọi người. Cảm ơn mọi người đã đọc tới đây. Dẫu biết rằng kiến thức mình vẫn hạn hẹp, tui hi vọng với nỗ lực này, tui có thể cung cấp cho mọi người ít nhiều kiến thức về loss function nói riêng và AI nói chung.
Trong project của mình, tui dự định sẽ dùng multi-task loss rồi sử dụng lại những loss kể trên cho từng task. Nhưng trước mắt trong tuần sau tui sẽ viết thêm 2 bài nữa, 1 về những model single-stage object detection, 1 về self-attention mechanism trong CNN. Căn bản nhất thì model mình sẽ kết hợp 3 yếu tố này, và dùng APs của COCO để evaluate model. Cố lên mấy bạn
Written by Phung Khanh Linh